
La Data Science est-elle une boîte noire ? Non. Peut-on utiliser un algorithme statistique sans comprendre son fonctionnement exact ? Non. Est-ce que tout le monde peut comprendre la Data Science ? Oui, du moins le fonctionnement globale.
Un bon algorithme de Data Science est le résultat d’une bonne compréhension d’une problématique métier, traduite techniquement par un Data Scientist. Pour déterminer LA bonne méthode à utiliser, il faut prendre en compte le problème (précisément, que cherche-t-on à savoir, prédire ?) et la capacité d’interprétation des résultats, puisqu’en finalité, seuls les résultats seront communiqués pour répondre à la problématique. On a donc un triptyque problématique – data science – conclusion. La Data science doit donc être une passerelle à sens unique entre la problématique et la conclusion. Elle permet de répondre à la question qui est posée, mais ne doit jamais servir à justifier des résultats.
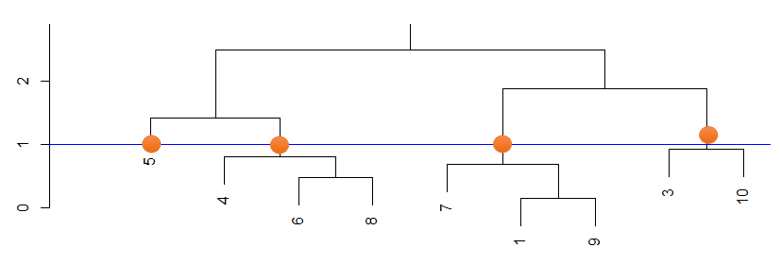
Une méthode statistique détaillée : La classification Ascendante Hiérarchique
L’objectif de cette méthode est de regrouper des individus (au sens statistique) dans des groupes, à l’intérieur desquels les individus sont très proches. C’est donc une méthode de segmentation qui peut être utilisée s’il n’y a pas de segments définis en amont. On suppose que le jeu de données donne des caractéristiques les individus à qui on souhaite attribuer un groupe. Au départ, chacun fait parti de son propre groupe et à chaque étape, l’algorithme décide de regrouper deux individus qui se ressemblent le plus au regard d’un critère mathématique. A la fin, l’algorithme a construit des groupes bien différenciables ! Il est ensuite possible d’identifier des indicateurs d’appartenance à un segment avec une analyse comparative des données de chaque groupe.
Retrouvez désormais notre 2ème article sur cette thématique de la Data Science. Cette fois-ci, notre expert se penche sur une deuxième méthode statistique : les K plus proches voisins.
Alexandre LANGLOIS
Data Scientist

