La Data Science est-elle une boîte noire ? Non. Peut-on utiliser un algorithme statistique sans comprendre son fonctionnement exact ? Non. Est-ce que tout le monde peut comprendre la Data Science ? Oui, du moins le fonctionnement global.
Dans le dernier article sur la vulgarisation des algorithmes de Data Science nous évoquions la classification ascendante hiérarchique. Aujourd’hui c’est une seconde méthode statistique que nous allons décortiquer.
2ème méthode statistique détaillée : les K plus proches voisins
C’est une méthode non paramétrique (qui ne dépend d’aucun paramètre à estimer) dont l’objectif est d’estimer pour chaque individu la probabilité conditionnelle d’appartenir à chacune des N classes.
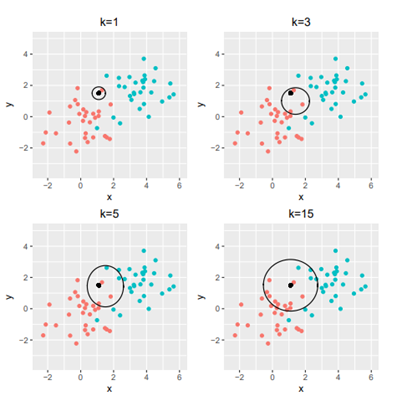
A partir d’un jeu de données où les individus ont un label (appartiennent à un groupe), l’idée principale pour estimer la probabilité conditionnelle est de calculer la proportion des voisins les plus proches autour de l’individu appartenant à chacune des classes, à l’aide d’une distance choisie en amont. C’est donc une méthode de classification supervisée, dans le sens où chaque individu est déjà intégré dans un groupe et le but est de minimiser les erreurs de classement, et donc de trouver le meilleur nombre de voisins pour pouvoir prédire la classe de chaque individu avec le moins d’erreur possible, ce qui permettra par la suite de classer un nouvel individu.
Cette méthode peut être vue comme une méthode géométrique : on va associer l’individu x à la classe C si la majorité de ses K plus proches voisins au sens de la distance euclidienne est de la classe C. Elle peut être couplée à une autre méthode de machine learning pour définir des groupes en amont.
Alexandre LANGLOIS
Data Analyst

